Overview
The Task Agent is inspired by CrewAI’s task functionality, allowing you to assign specific and well-defined tasks to individual agents. Each Task Agent encapsulates a single task with structured prompt, expected output, and responsible agent, creating a clear and focused work unit. This pattern is fundamental for creating organized agent systems, where each agent has specific and well-defined responsibilities, similar to the “tasks” concept in CrewAI that enables efficient orchestration of specialized agent teams.Inspired by CrewAI: Implementation based on the CrewAI Tasks concept for structured task assignment to specialized agents.
Key Features
One Task per Agent
Each Task Agent encapsulates exactly one specific task
Structured Prompt
Clear and detailed task prompt for the assigned agent
Expected Output
Clear definition of the expected task result
Assigned Agent
Selection of specific agent responsible for execution
When to Use Task Agent
Ideal Scenarios
Ideal Scenarios
✅ Use Task Agent when:
- Well-defined tasks: You have a specific and clear task
- Single responsibility: One agent should be responsible for one task
- Structured output: You know exactly what to expect as a result
- Specialization: Agent has specific expertise for the task
- Simple orchestration: Task is part of a larger process
- Sentiment analysis of specific text
- Executive summary generation from a report
- Input data validation
- Content translation to specific language
- Information extraction from documents
When NOT to use
When NOT to use
❌ Avoid Task Agent when:
- Multiple tasks: Need to execute several related tasks
- Complex workflow: Requires conditional logic or loops
- Agent interaction: Agents need to collaborate directly
- Dynamic process: Workflow changes based on results
- Too simple task: Can be solved with direct prompt
Creating a Task Agent
Step by Step on Platform
1. Start creation
1. Start creation
- On the Evo AI main screen, click “New Agent”
- In the “Type” field, select “Task Agent”
- You’ll see specific fields for task configuration
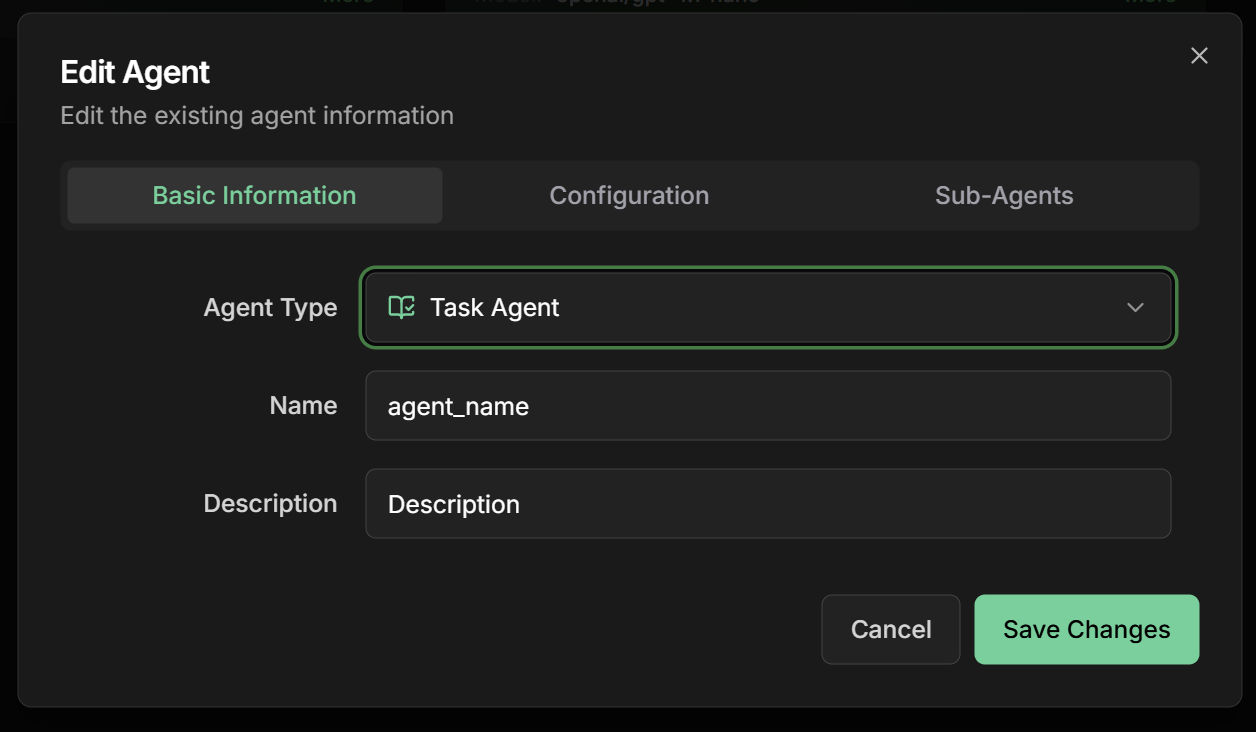
2. Configure basic information
2. Configure basic information
Name: Descriptive name of the taskDescription: Summary of the specific taskGoal: Specific objective of the task
3. Select responsible agent
3. Select responsible agent
Assigned Agent: Choose the agent that will execute the taskAvailable options: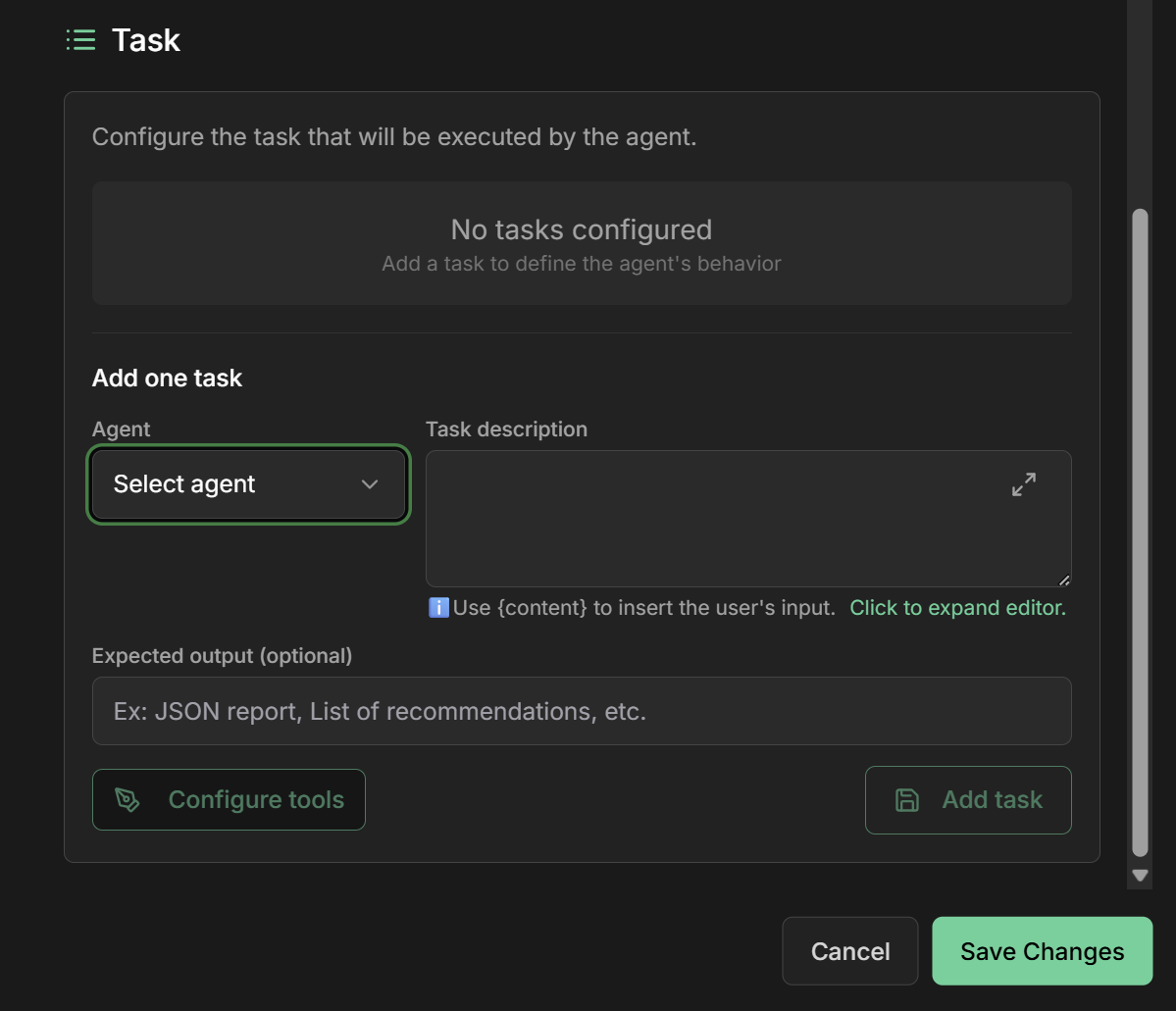
- Existing LLM agents on the platform
- Configured A2A agents
- Previously created specialized agents
- Agent specialization in the task area
- Required technical capabilities
- Historical performance on similar tasks
- Availability and resources
4. Define task prompt
4. Define task prompt
Task Prompt: Detailed and specific prompt for the taskRecommended structure:
5. Define expected output
5. Define expected output
Expected Output: Clear and detailed description of expected resultExpected output structure:Output specifications:
- Format: Structured JSON
- Required fields: All main fields must be present
- Data types: Specify types (string, number, array, object)
- Validation: Criteria to validate if output is correct
- Examples: Concrete examples of expected format
6. Advanced configurations
6. Advanced configurations
Timeout: Time limit for task executionRetry Policy: Retry policy in case of failureOutput Validation: Automatic result validationContext Injection: Additional context injection
7. Output Key - State Sharing
7. Output Key - State Sharing
Output Key field in interface:The Output Key allows the Task Agent to save the task result in a specific variable in the shared state, making it available for other agents or subsequent tasks.How it works:- Configure the
Output Keyfield with a descriptive name - The task result will be automatically saved in this variable
- Other agents can access using placeholders
{{output_key_name}} - Works in workflows, loops, and multi-agent systems
- Use snake_case:
task_result,processed_data - Be specific:
form_validationinstead ofvalidation - Avoid conflicts with other state variables
- Document output format in instructions
- Use names that reflect task content
Practical Examples
1. Product Review Sentiment Analysis
Complete Configuration
Complete Configuration
Scenario: Analyze sentiment of product reviews for e-commerceTask Agent Configuration:Basic Information:Expected Output:
- Name:
sentiment_analysis_task - Description:
Detailed sentiment analysis of product reviews - Goal:
Provide actionable insights about customer satisfaction
- Assigned Agent:
sentiment_specialist_v2 - Agent Type: Specialized LLM Agent
- Specialization: Sentiment analysis in Portuguese
2. Executive Summary Generation
Complete Configuration
Complete Configuration
Scenario: Generate executive summary of long reportsTask Agent Configuration:Basic Information:Expected Output:
- Name:
executive_summary_task - Description:
Generation of concise and informative executive summaries - Goal:
Create summaries that capture key points for decision-making
- Assigned Agent:
document_summarizer_pro - Specialization: Corporate document summarization
3. Input Data Validation
Complete Configuration
Complete Configuration
Scenario: Validate form data before processingTask Agent Configuration:Basic Information:Expected Output:
- Name:
data_validation_task - Description:
Intelligent validation of input data - Goal:
Ensure data quality and completeness before processing
- Assigned Agent:
data_validator_agent - Specialization: Data validation and cleaning
Integration with Other Agents
Using Task Agents in Workflows
In Sequential Workflows
In Sequential Workflows
Example: Content Processing Pipeline
In Parallel Workflows
In Parallel Workflows
Example: Complete Product Analysis
In Workflow Agents
In Workflow Agents
Example: Complex Visual Workflow
Monitoring and Performance
Tracking Task Agents
Performance Metrics
Performance Metrics
Specific metrics for Task Agents:Execution Metrics:
Debugging and Troubleshooting
Debugging and Troubleshooting
Common issues with Task Agents:1. Output Format Mismatch2. Task Scope Creep3. Quality Inconsistency4. Performance Degradation
Best Practices
Effective Task Design
Effective Task Design
Principles for effective Task Agents:
- Single responsibility: One specific and well-defined task
- Clear prompt: Precise and unambiguous instructions
- Structured output: Well-specified output format
- Appropriate agent: Choose agent with appropriate specialization
- Robust validation: Clear criteria to validate result
Agent Specialization
Agent Specialization
Task-agent matching:
- Text analysis: Use agents specialized in NLP
- Data processing: Use agents with analytical capabilities
- Content generation: Use creative and specialized agents
- Validation: Use agents focused on quality and precision
- Translation: Use specialized multilingual agents
Quality and Reliability
Quality and Reliability
Ensuring consistent execution:
- Testing: Test tasks with different inputs
- Validation: Implement automatic output validation
- Monitoring: Continuously monitor performance and quality
- Feedback loop: Use results to improve prompts
- Version control: Maintain history of task changes
Common Use Cases
Content Analysis
Analytical Tasks:
- Sentiment analysis
- Entity extraction
- Text classification
- Document summarization
Data Processing
Data Tasks:
- Input validation
- Data cleaning
- Format transformation
- Information enrichment
Content Generation
Creative Tasks:
- Summary generation
- Report creation
- Text translation
- Document formatting
Verification and Quality
Control Tasks:
- Compliance verification
- Quality control
- Data auditing
- Rule validation
Next Steps
Workflow Agent
Use Task Agents in complex visual workflows
Sequential Agent
Combine Task Agents in ordered sequences
LLM Agent
Understand the agents that execute tasks
A2A Agent
Use external agents as task executors
The Task Agent is perfect for creating well-defined and specialized work units. Use it when you want to assign specific responsibilities to specialized agents, following the CrewAI pattern for efficient organization of agent teams.